自己的真实痛点催生的工具——港卡汇款渠道混乱、券商没有盈亏拆分。独立用 AI 辅助完成从 0 到 1 的交付,也是第一次在"踩坑之后"理解了什么叫产品留存。
在云服务器上部署并深度使用 Hermes 开源 Agent 系统。不是因为FOMO也不是为了炫技,是为了真正理解一个 AI Agent 是如何运作的,能带来哪些落地场景。
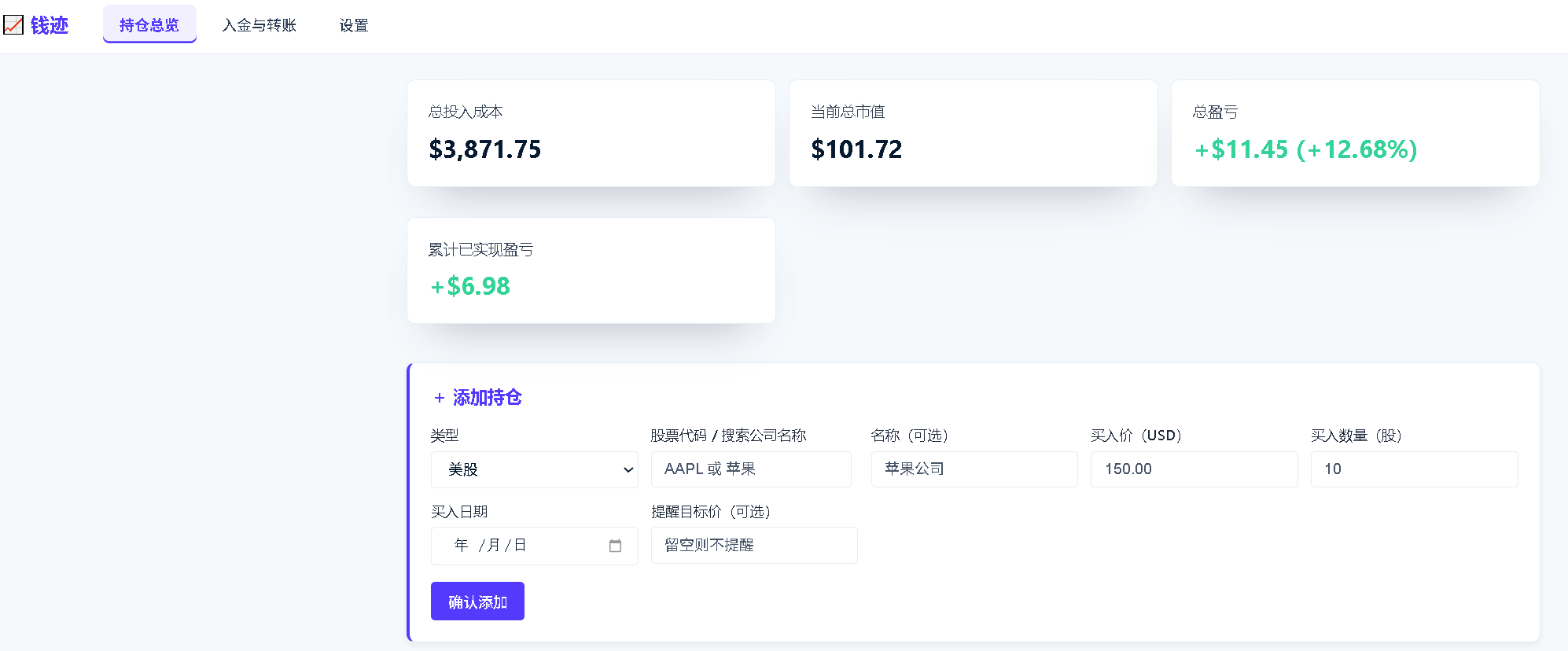
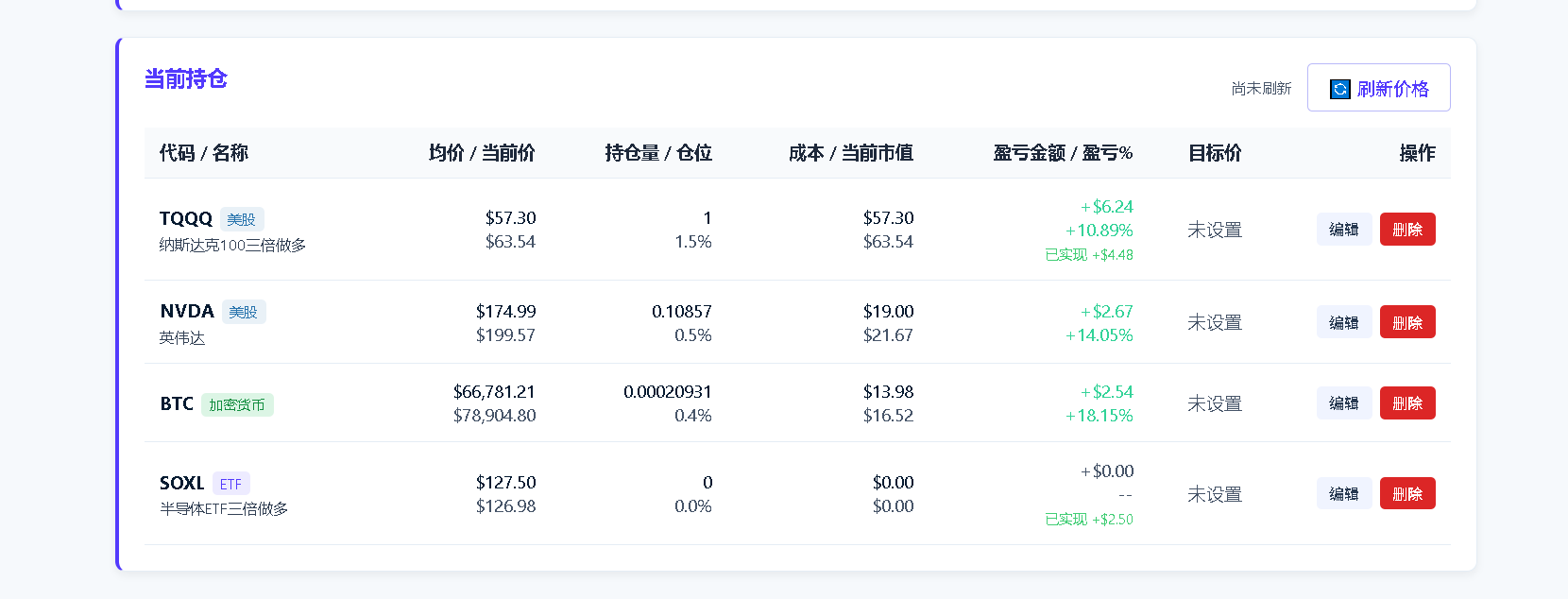
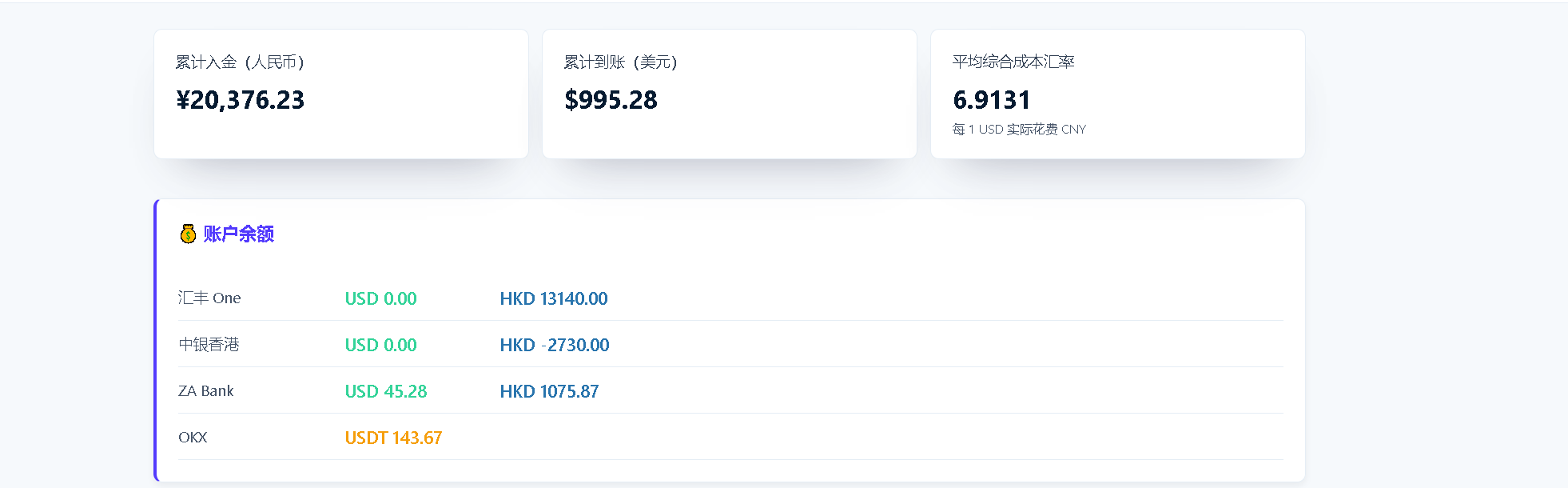
开通港卡进入港美股市场后,跨境汇款横跨多条渠道——跨境电汇、跨境支付通、中银快汇——分散于不同银行,综合汇率成本难以追踪。所用券商亦缺乏「已实现 / 未实现盈亏」拆分,持仓数据不透明。
两个来自真实场景的需求,用一个轻量工具即可解决。钱迹由此立项。
技术执行不是核心瓶颈——Claude Code 显著压缩了开发周期。真正的挑战在于:动手前未对标同类产品、未厘清核心需求,导致方向反复;开发过程中缺乏项目背景文档与代码规范,AI 生成的代码风格不一、难以维护;同时没有建立版本控制意识,出现问题时无从定位根因。
缺乏 Roadmap 的另一面是低估了「录入门槛」。每笔汇款与交易均需手动记录,新鲜感消退后录入成本持续高于使用价值,工具最终搁置。
① 动手前先厘清需求 — 明确自己真正想要什么,找到对标产品,在写第一行代码前完成需求对齐。没有清晰的起点,方向会在执行中持续漂移。
② 建立开发规范 — 正式开发前需要一套完整的规范体系:项目背景文档、技术栈选型、代码风格与格式要求。规范不是负担,是让 AI 协作真正有效的前提。
③ 始终掌握项目全局 — AI Coding 只是提效手段,开发者需要清楚整体架构、当前阶段、每次改动的影响范围与版本变化。失去全局感,AI 会把项目带偏。
④ 留存靠降低录入成本 — 若重来,我会先厘清用户在哪个时刻产生数据,在那个节点做自动采集,而非依赖用户主动填报。
「AI 加速执行,不替代判断」——用 Claude Code 生成代码只是提效手段,若无法理解输出内容,AI 就是黑箱,产品掌控力无从建立。
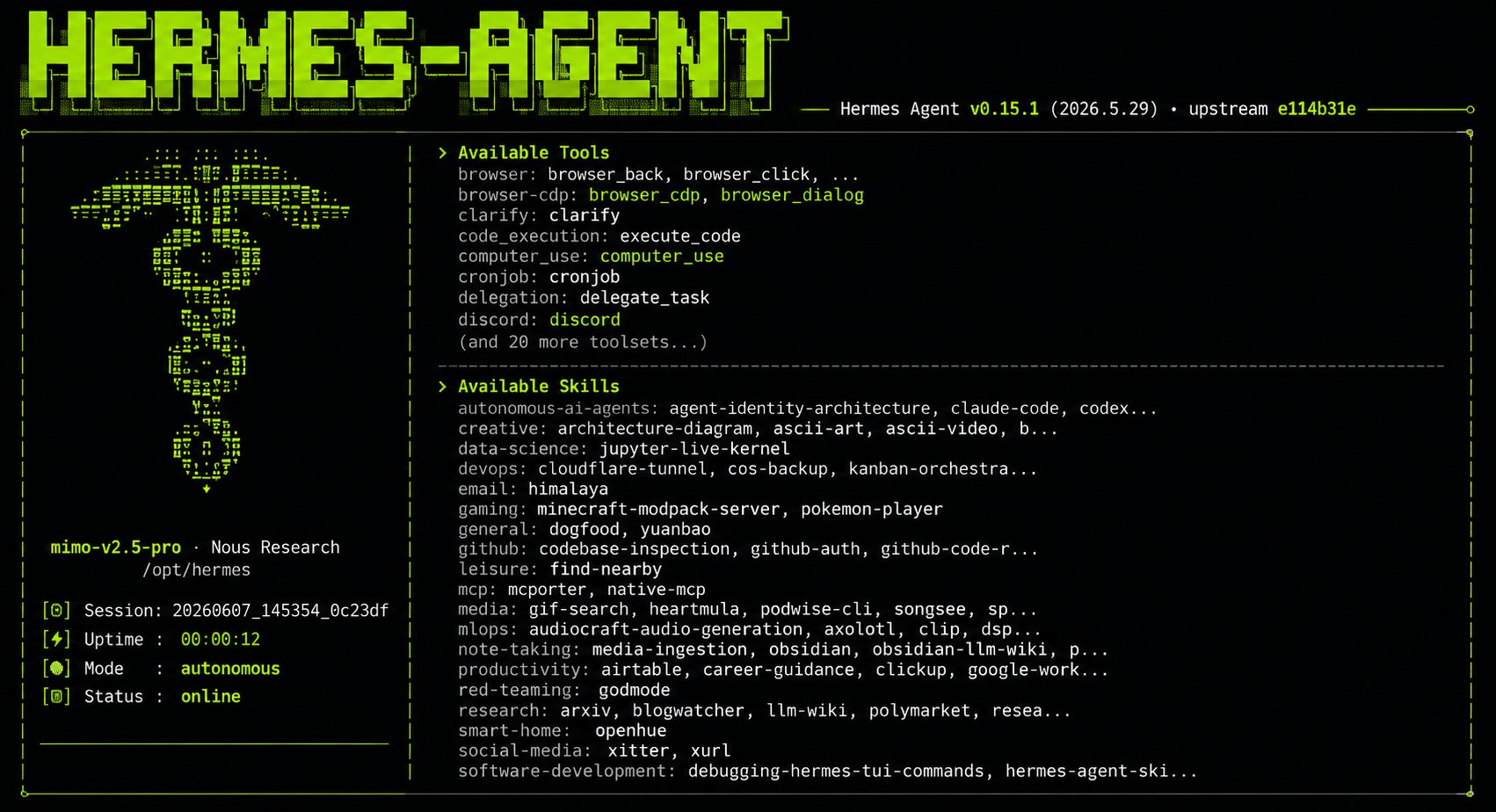
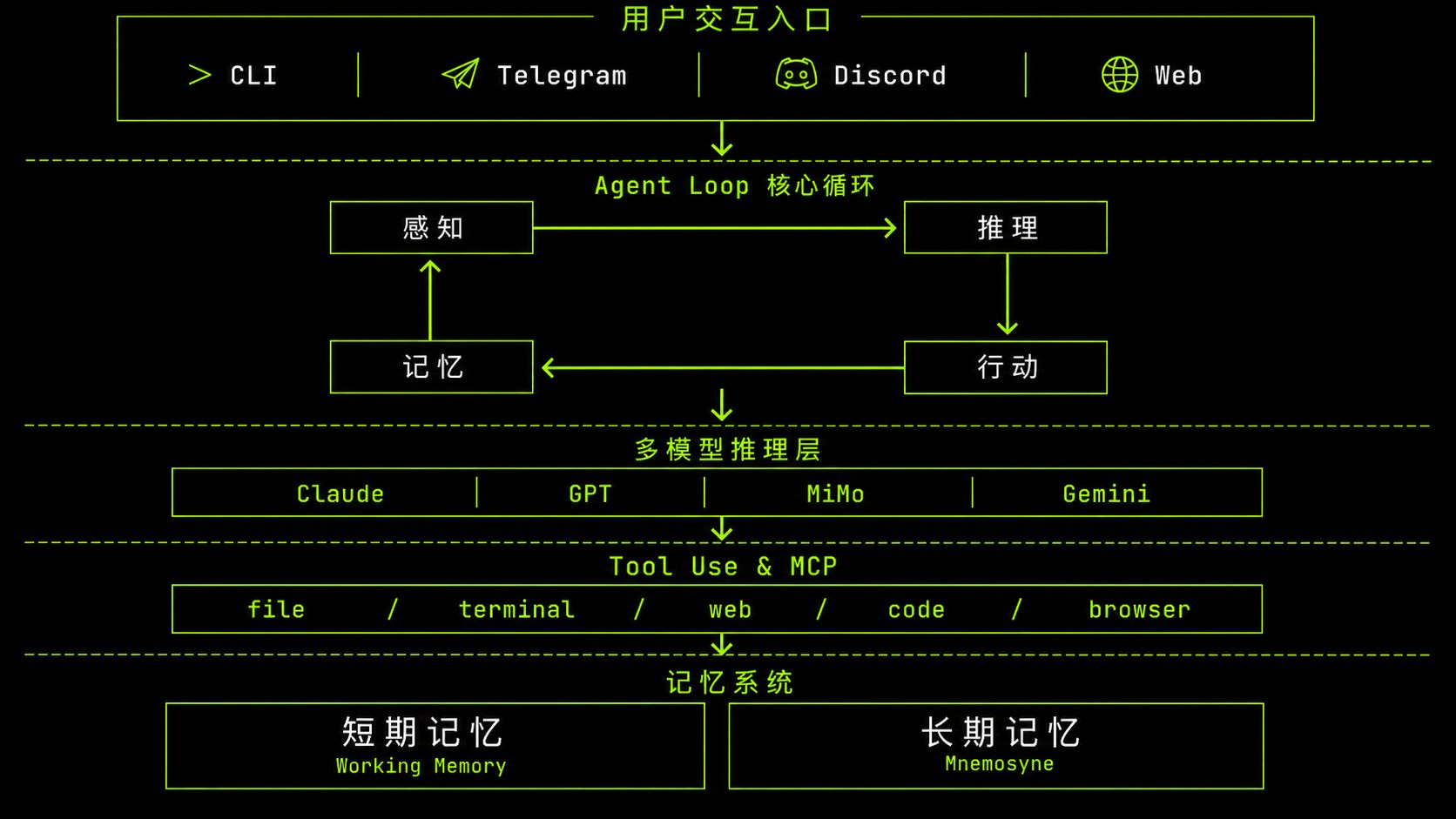
GPT 与 Claude 功能完善,但本质上是封闭的对话产品——模型固定、记忆受限、无法持续在线、行为边界由平台定义。Hermes 的价值在于另一层:自由选择底层模型、自定义 Agent 行为、构建持久记忆、7×24 小时运行。
部署它的动机有三层:亲身体验一个真正可配置的 Agent 系统是如何运作的;从工程层面理解 AI Agent 的底层架构;探索 Agent 能在哪些真实场景中完成持续性的内容任务。目标是建立对 Agent 系统的第一手认知,而非停留在「调用 API」的层面。
环境层 · 从零开始在 Ubuntu 云服务器上通过 Docker 完成部署。一开始对 Docker 和 Linux 一无所知,在反复踩坑中逐渐摸清了镜像、Dockerfile、Docker Compose 的工作逻辑,也积累了基本的 Linux 运维感觉。
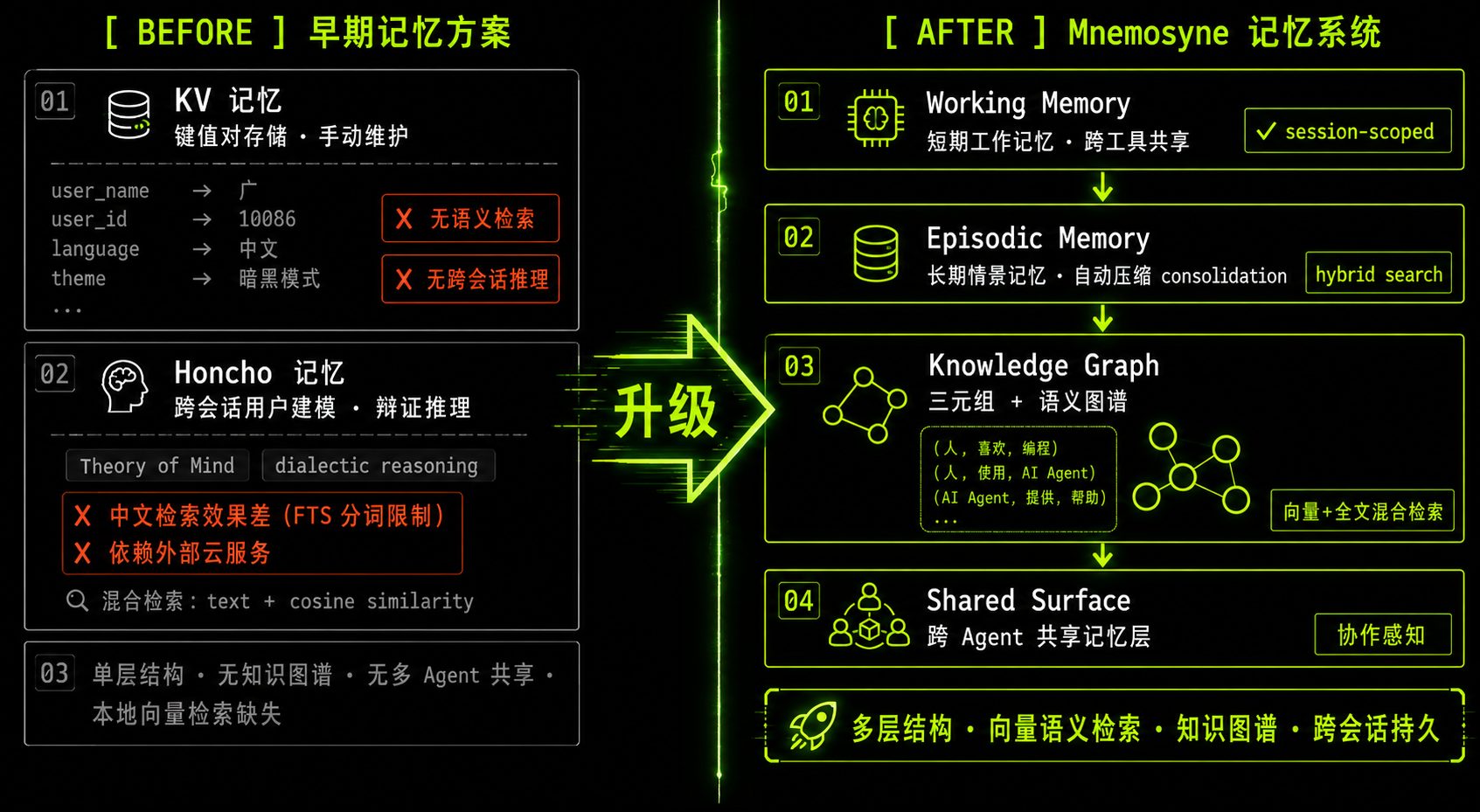
软件层 · 理解了这个 Agent 本质是一个 Python 应用框架,逐层拆解其架构——LLM 负责推理、Tool use 定义能力边界、MCP 扩展工具调用、记忆系统决定上下文持久化。记忆系统分为两层:短期记忆(context window 内的当前对话)与长期记忆(向量数据库存储与检索),改造后检索命中率达 85%+。在此基础上落地了自己对 Harness Engineering 的理解,也真正体会到「记忆」对 Agent 持续运作的核心价值。
① Agent 出问题时,不要急着纠正输出——先追问为什么架构会导致这个结果,再从根本上修改。
② 人在 Agent 循环中的角色是架构设计者,而非逐环节的干预者。LLM 的输出本就有不确定性,真正的掌控在于设计好循环结构。
③ 人是 Agent 结果的最终判断与验收者。只有自己清楚「好」的标准,才能让 Agent 持续生成好的输出。
④ 需要与 Agent 建立共识、缩小信息差——文件路径、风格要求、输出规范,都需要提前约定清楚。